
Qwen3-TTS
Collection
7 items
•
Updated
•
294
Qwen3-TTS Technical Report | GitHub Repository | Hugging Face Demo
Qwen3-TTS is a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS supports state-of-the-art 3-second voice cloning and description-based control.
This specific checkpoint is the 0.6B Base model, which is capable of rapid voice cloning from a user-provided audio input.
pip install -U qwen-tts
# Optional: for optimized performance
pip install -U flash-attn --no-build-isolation
To clone a voice and synthesize new content using the Base model, you can use the following code snippet:
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# Load the model
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-0.6B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# Reference audio for cloning
ref_audio = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/clone.wav"
ref_text = "Okay. Yeah. I resent you. I love you. I respect you. But you know what? You blew it! And thanks to you."
# Generate speech
wavs, sr = model.generate_voice_clone(
text="I am solving the equation: x = [-b ± √(b²-4ac)] / 2a? Nobody can — it's a disaster (◍•͈⌔•͈◍), very sad!",
language="English",
ref_audio=ref_audio,
ref_text=ref_text,
)
# Save the resulting audio
sf.write("output_voice_clone.wav", wavs[0], sr)
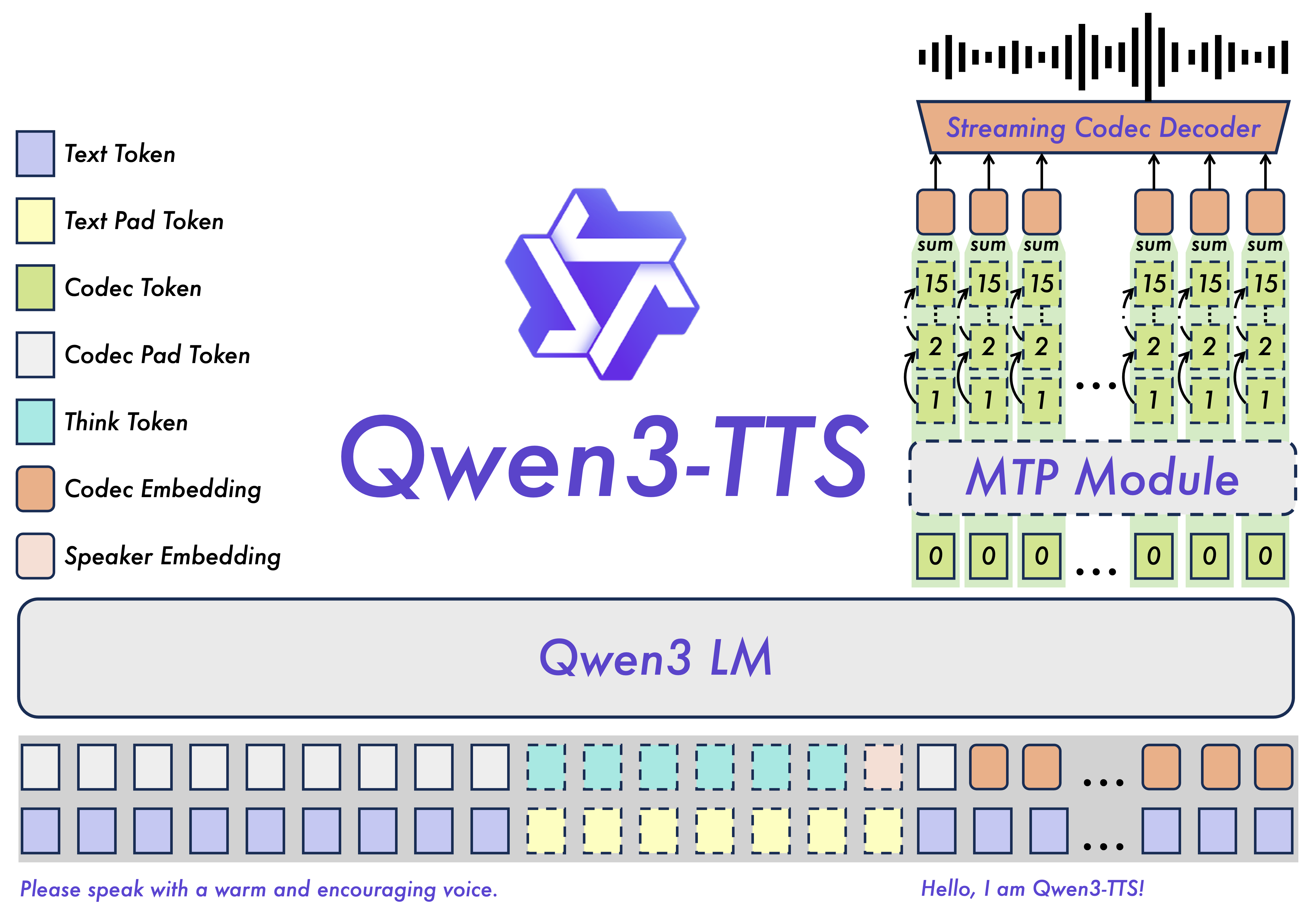
Qwen3-TTS covers 10 major languages (Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian) as well as multiple dialectal voice profiles to meet global application needs. Key features:
If you find this work useful, please consider citing the technical report:
@article{Qwen3-TTS,
title={Qwen3-TTS Technical Report},
author={Hangrui Hu and Xinfa Zhu and Ting He and Dake Guo and Bin Zhang and Xiong Wang and Zhifang Guo and Ziyue Jiang and Hongkun Hao and Zishan Guo and Xinyu Zhang and Pei Zhang and Baosong Yang and Jin Xu and Jingren Zhou and Junyang Lin},
journal={arXiv preprint arXiv:2601.15621},
year={2026}
}